
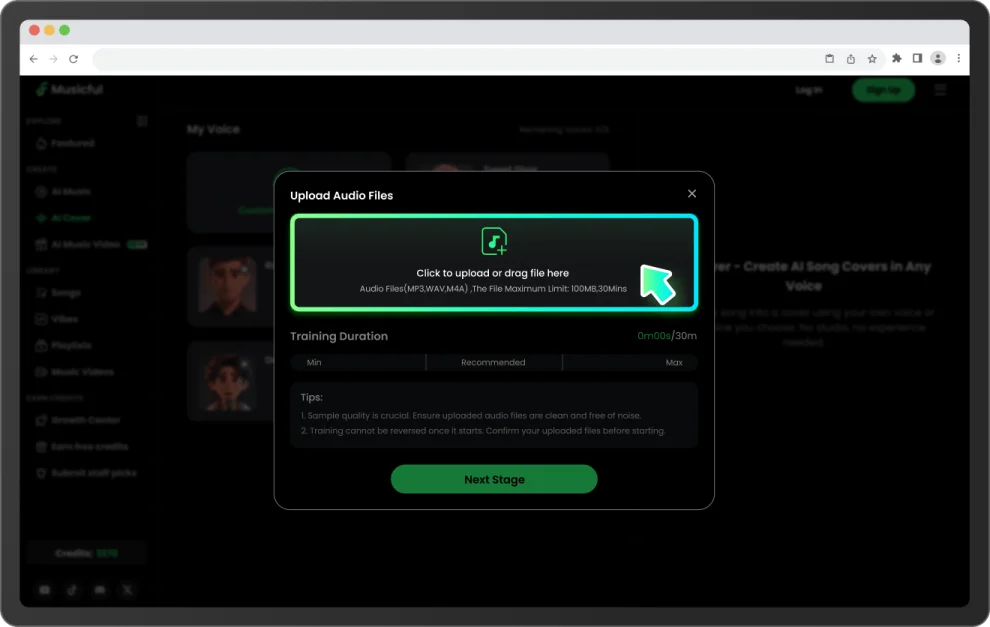
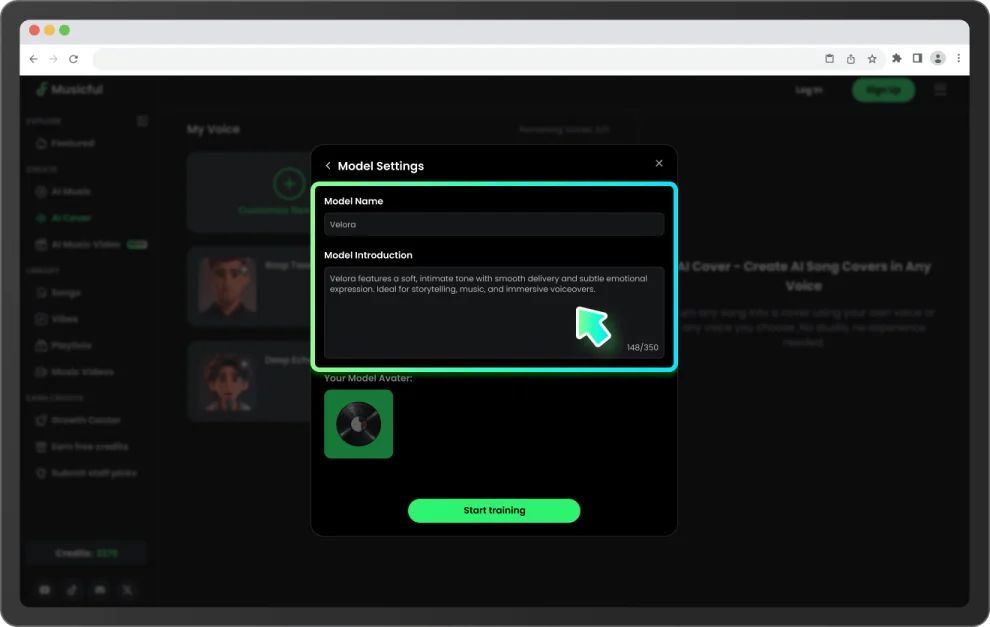
訓練你的專屬聲音模型
上傳幾分鐘音訊,Musicful 就會自動建立個人聲音模型,捕捉你的音色、音高與聲線特徵。

Remaining Voices: 0 /0
選一首歌、挑一個聲音或訓練專屬音色,幾分鐘內完成媲美錄音室的 AI 翻唱。
選擇下方的聲音模型,聽聽同一首歌換成完全不同的聲音後會是什麼感覺。幾分鐘內就能做出你自己的 AI 翻唱。

Sweet Glow
柔和明亮
* 所有示範音軌皆為原創作品,僅供展示用途。
從聲音訓練到最終匯出,Musicful 提供你打造 AI Song Covers 所需的完整工具,讓成品真正聽起來像你在唱。
上傳幾分鐘音訊,Musicful 就會自動建立個人聲音模型,捕捉你的音色、音高與聲線特徵。
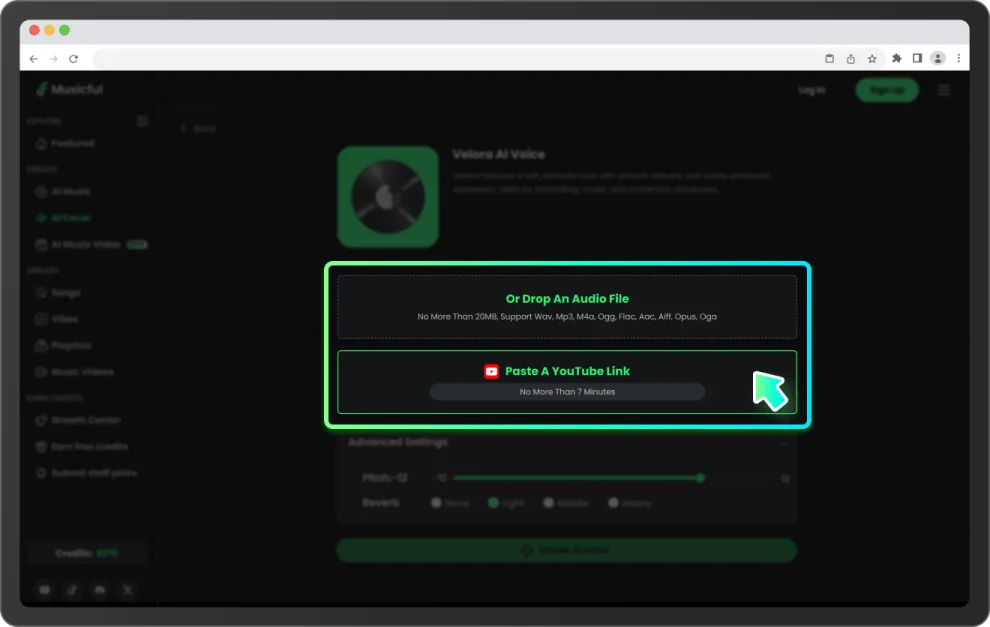
上傳音檔或貼上 YouTube 連結。Musicful 可使用你的聲音模型,生成屬於你聲音版本的新演唱,適用各種曲風與風格。
大多數 AI 翻唱可在 15 分鐘內完成。無需漫長渲染,也不用繁瑣設定,直接獲得乾淨自然、可立即播放或分享的翻唱作品。
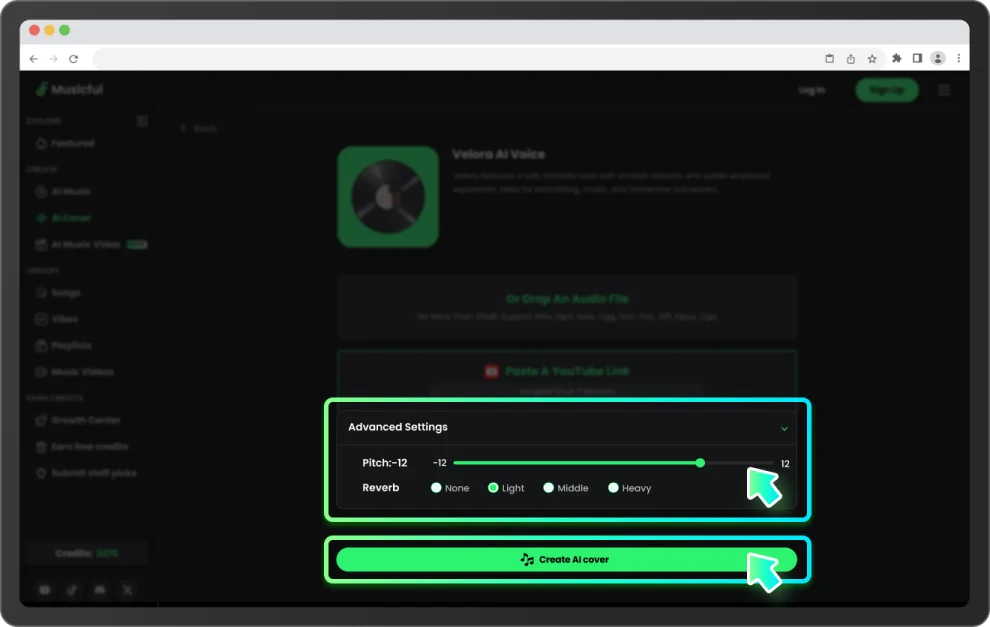
生成前可在進階設定中調整音高與混響。小幅調整,也可能大大改變最終效果。
你不需要 DAW、麥克風設備或技術背景。只要上傳音訊,剩下的都交給 Musicful。
將翻唱匯出為高品質音訊檔,隨時分享到社群媒體、串流平台或個人專案。
你不必是音樂人。只要你有聲音,也有一首想翻唱的歌,今天就能開始做 AI 翻唱。
只要用短短幾分鐘音訊訓練聲音模型,之後你幾乎可以翻唱任何歌曲,而且聽起來就像是你親自唱的一樣。

只要用幾分鐘音訊訓練一次,之後生成的翻唱作品就會像你本人在演唱。
你可以用兩種方式開始——訓練自己的聲音模型,或直接使用已建立好的聲音。
無論你是音樂人、內容創作者,還是單純好奇自己的聲音會是什麼效果—— 以下就是大家實際使用它的方式。
很多人心裡都有一份多年來一直想錄的歌單。可能設備不對、時機不對,或只是一直沒真的開始。只要訓練一次聲音模型——幾分鐘音訊就夠——那份歌單就不再只是想像。無需錄音室,無需樂隊,直接把歌做出來。

真正好聽、又不踩版權風險的音訊,比想像中更難找。不如直接用你的聲音生成翻唱——原創、貼合內容,而且在你需要的當天就能完成。

為了測試一個想法就找歌手錄音,成本很高。在腦中想像,和真正聽到音軌成品,完全是兩回事。現在你可以快速做出 demo——足夠拿去和客戶分享,也足夠判斷這個方向值不值得繼續做。

你不一定想衝播放量,也不一定想經營個人品牌。你只是喜歡創作。訓練一個屬於自己的聲音模型,翻唱你喜歡的歌,之後要不要分享給別人聽,再決定就好。

說真的,有些人只是想知道自己聽起來會是什麼樣子。這完全是很合理的理由。訓練模型、選一首歌、聽聽看——通常不到十分鐘就能完成。

很多人心裡都有一份多年來一直想錄的歌單。可能設備不對、時機不對,或只是一直沒真的開始。只要訓練一次聲音模型——幾分鐘音訊就夠——那份歌單就不再只是想像。無需錄音室,無需樂隊,直接把歌做出來。

真正好聽、又不踩版權風險的音訊,比想像中更難找。不如直接用你的聲音生成翻唱——原創、貼合內容,而且在你需要的當天就能完成。

為了測試一個想法就找歌手錄音,成本很高。在腦中想像,和真正聽到音軌成品,完全是兩回事。現在你可以快速做出 demo——足夠拿去和客戶分享,也足夠判斷這個方向值不值得繼續做。
你不一定想衝播放量,也不一定想經營個人品牌。你只是喜歡創作。訓練一個屬於自己的聲音模型,翻唱你喜歡的歌,之後要不要分享給別人聽,再決定就好。
說真的,有些人只是想知道自己聽起來會是什麼樣子。這完全是很合理的理由。訓練模型、選一首歌、聽聽看——通常不到十分鐘就能完成。






